

Șiruri de caractere în C++. Funcții cu șiruri de caractere
În C++ există două modalități principale de a lucra cu șirurile de caractere (string-urile). Cea mai ușor de folosit, însă ineficientă în anumite situații, este clasa std::string din STL, care practic este un std::vector de caractere, căruia i s-a adăugat niște funcționalitate specifică șirurilor de caractere. În acest articol voi prezenta modalitatea moștenită din limbajul C, și anume reprezentarea string-urilor drept vectori cu elemente de tip char, terminați prin caracterul '\0'. Înțelegerea acestui articol necesită cunoștințe legate de pointeri și funcții.
Reprezentarea șirurilor de caractere cu terminator nul
După cum am zis, în C++ șirurile de caractere sunt vectori cu elemente de tip char, terminați prin caracterul '\0', numit terminator nul. Este bine de știut că acest caracter are codul ASCII 0.
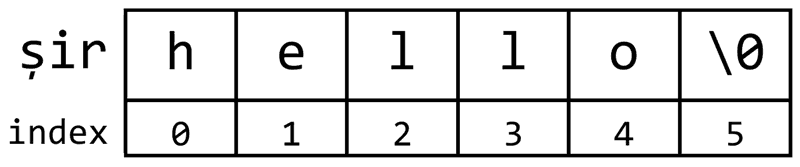
Deci, dacă vrem să reținem un șir de caractere de lungime maximă n (de maxim n caractere), va trebui să declarăm un vector cu n + 1 elemente, pentru că ultima poziție trebuie să fie ocupată de terminatorul nul. Șirurile de caractere pot fi inițializate la declarare folosind constante de forma "text". De exemplu, pentru a declara un șir de caractere care să rețină cuvântul "string", vom scrie:
char str[7] = "string"; // Lungimea lui str trebuie să fie minim 7.Dacă tot inițializăm șirul de caractere cu constanta "string", putem să nu-i mai specificăm dimensiunea, căci aceasta va fi dedusă de compilator drept lungimea constantei + 1. Asta poate fi o problemă însă, în cazul în care, pe viitor, vom avea nevoie să stocăm în str un șir de lungime mai mare decât a lui "string".
char str[] = "string";Evident, caracterele ce compun un string sunt indexate de la 0. Asta implică faptul că ultimul caracter al șirului se află pe poziția len - 1, iar pe poziția len se află terminatorul nul, unde len este lungimea șirului. Voi explica mai încolo cum putem indexa string-urile de la 1. Accesarea unui caracter se face exact ca la orice vector: str[poz].
Citirea și afișarea șirurilor de caractere
Afișarea unui șir de caractere se efectuează foarte ușor folosind operatorul << (inserție în stream):
cout << str;Citirea folosind >>
Citirea folosind operatorul >> (extragere din stream) va introduce caractere în șirul citit până la întâlnirea primului caracter alb (spațiu, tab sau enter), care va rămâne necitit. La finalul șirului se va adăuga automat terminatorul nul.
cin >> str;Evident, dimensiunea cu care declarăm vectorul str ar trebui să fie mai mare strict decât lungimea șirului ce urmează a fi citit în acesta. Altfel, în mod normal, se va produce o eroare de tipul segmentation fault.
Citirea folosind getline
Pentru a citi șiruri de caractere ce conțin eventuale spații, putem folosi metoda getline a obiectelor de tipul istream (a stream-urilor de intrare, precum cin). Aceasta se apelează astfel:
in.getline(str, SMAX);in este fișierul de intrare, str șirul citit, iar SMAX numărul maxim de caractere ce vrem să fie citite (cu tot cu terminatorul nul, care se adaugă automat). Această funcție introduce caractere în str până la primul enter, sau până când lungimea șirului devine SMAX - 1. Dacă citirea se oprește pentru că s-a ajuns la enter, atunci acesta va fi parsat (citit), fără a fi însă adăugat la șir. Fie următorul apel al funcției getline:
fin.getline(str, 5);Să presupunem că linia curentă a fișierului fin ar conține textul "abcdef", și că citirea cu getline începe cu 'a'. (Am fixat asta deoarece getline poate începe și de la mijlocul liniei; depinde unde am ajuns anterior cu citirea datelor.) După apelul de mai sus, str ar conține șirul "abcd". În schimb, dacă în loc de 5 am fi avut 7 sau mai mult, str ar fi conținut șirul "abcdef".
Funcția getline poate fi apelată și în următoarea variantă:
in.getline(str, SMAX, chr);Diferența este că în acest caz se vor citi caractere până la întâlnirea delimitatorului chr, care va fi citit fără să fie adăugat la șir. Citirea se poate opri de asemenea dacă s-a ajuns la enter, sau dacă s-au citit SMAX - 1 caractere.
Citirea caracterelor
Cred că este momentul potrivit să reamintesc care sunt cele trei modalități de a citi caractere:
cin >> chr; // Se citește în chr primul caracter care nu este alb.cin.get(chr); // Se citește în chr următorul caracter, alb sau nu.cin.get(); // Se sare peste următorul caracter, alb sau nu.Metoda get fără parametri este îmbinată adesea cu citirea string-urilor. De exemplu, avem următorul text, pe care dorim să-l citim linie cu linie:
stringsir de caractereA doua linie conține spații, pe când prima nu, așa că ne gândim să procedăm astfel:
cin >> str1;cin.getline(str2, 100);Este corect? Nu. Funcția getline va începe citirea cu caracterul newline de pe prima linie, și o va termina tot atunci. Pentru a rezolva asta, putem apela cin.get() după ce citim primul string, pentru a parsa enter-ul:
cin >> str1; cin.get();cin.getline(str2, 100);Pointerii la char și șirurile de caractere
Definiția în care șirurile de caractere sunt vectori nu este tocmai adevărată. Pentru a o corecta, cuvântul „vector” ar trebui înlocuit cu „secvență continuă de memorie”. O astfel de secvență nu începe neapărat cu primul element dintr-un vector de char. Ea poate începe și cu al doilea element, și cu al treilea… Aparent, până acum, pentru a ne referi la un string am folosit numele vectorului său corespunzător. De fapt, foloseam un pointer la primul element din acesta (str[0]), pentru că de acolo începea șirul nostru. (Pentru cine nu știe, numele unui vector este chiar un pointer la începutul său.) Dacă string-ul începe la poziția x, sau dacă, spre exemplu, începe la poziția 0, dar vrem să ne referim la substring-ul care începe la poziția x, vom scrie str + x.
char str[] = "InfoGenius";cout << str << '\n'; // InfoGeniuscout << (str + 4) << '\n'; // GeniusAcum este ușor să ne dăm seama cum putem indexa un șir de caractere de la 1: Avem grijă să-l declarăm cu un element în plus, pentru că îi vom ignora prima poziție. Apoi, de fiecare dată când ne vom referi la el, în loc de str, vom scrie str + 1.
cin >> (str + 1);cout << (str + 1);Folosind operatorul =, putem atribui unui pointer la char adresa de început a unui șir de caractere. Apoi, vom putea folosi acest pointer ca și cum chiar el este șirul. Vom avea nevoie de asta atunci când vom căuta toate aparițiile unui string într-un alt string.
char str[] = "arbori\0de\0intervale";char *ptr1 = str;char *ptr2 = str + 7;char *ptr3 = str + 10;cout << ptr1 << ' ' << ptr2 << ' ' << ptr3 << '\n'; // arbori de intervaleFuncții predefinite pentru șiruri de caractere
Este destul de simplu să efectuăm operații de bază cu șirurile de caractere, cum ar fi ștergerea unui caracter, determinarea lungimii, concatenarea a două șiruri etc. Însă, aceste operații pot apărea într-un număr foarte mare de locuri în cadrul unui program, așa că C++ ne pune la dispoziție biblioteca <cstring>, ce conține un set de funcții pentru prelucrarea șirurilor de caractere. În continuare le voi prezenta pe cele mai importante dintre ele.
Funcția
strlen
Funcția strlen returnează lungimea string-ului str. Aceasta este determinată în unde este lungimea șirului, deoarece se parcurg toate caracterele până la întâlnirea terminatorului nul.
char str[] = "C++";cout << strlen(str) << '\n'; // 3cout << strlen(str + 2) << '\n'; // 1cout << strlen("string") << '\n'; // 6Funcția
strcpy
Funcția strcpy copiază conținutul lui src în șirul care începe la poziția indicată de dest, cu tot cu terminatorul nul. În plus, strcpy returnează pointer-ul dest, ceea ce ne ajută să efectuăm copieri înlănțuite, ca pe ultima linie din exemplu.
char a[10], b[10]; // a: | b:strcpy(a, "Info"); // a: Info | b:strcpy(b, "Genius"); // a: Info | b: Geniusstrcpy(a + 4, b); // a: InfoGenius | b: Geniusstrcpy(strcpy(b, a) + 10, ".ro"); // a: InfoGenius | b: InfoGenius.roAtenție! Apelul funcției strcpy când dest și src se suprapun poate provoca undefined behaviour (crash de cele mai multe ori). De exemplu:
char str[] = "0123456789";strcpy(str, str + 5); // Undefined behaviourComplexitatea funcției strcpy este unde este lungimea lui src.
Funcția
strcat
Funcția strcat concatenează șirurile dest și src, adică îl copiază pe src (cu tot cu terminatorul nul) la finalul lui dest. La fel ca strcpy, strcat returnează adresa destinației, pentru a permite efectuarea de concatenări înlănțuite. Funcția strcat provoacă și ea undefined behaviour când dest și src se suprapun în memorie.
char a[] = "Info", b[] = "InfoGenius";strcat(a, b + 4);cout << a << '\n'; // InfoGeniusComplexitatea funcției strcat este unde este lungimea lui dest și lungimea lui src. Asta pentru că strcat parcurge mai întâi șirul destinație, pentru a găsi poziția unde se află terminatorul nul, iar abia apoi copiază conținutul sursei, începând de la acea poziție.
Funcția
strncpy
Funcția strncpy este foarte asemănătoare cu strcpy, doar că nu copiază tot șirul src în dest, ci doar primele nr caractere din el. Asta înseamnă implicit că la final nu adaugă terminatorul nul la destinație, așa că trebuie să fim atenți să îl punem noi atunci când este cazul. Dacă nr depășește lungimea sursei, ultimele nr - strlen(src) caractere adăugate vor fi nule.
char a[20] = "informatica", b[] = "ingenios";strncpy(a + 4, b + 2, 6); a[10] = '\0'; a[8] = 'u';cout << a << '\n'; // infogeniusFuncția
strncat
Funcția strncat este la rândul ei asemănătoare cu strcat, doar că nu concatenează șirurile dest și src, ci doar destinația și subșirul format din primele nr caractere ale sursei. Spre deosebire de strncpy, strncat adaugă singur terminatorul nul la finalul noului șir. Dacă nr este mai mare decât lungimea sursei, la finalul lui dest se va lipi tot șirul src, și nimic mai mult.
char a[50] = "A fi", b[50] = "A fi sau a nu fi. Aceasta este intrebarea.";strncat(a, b + 4, 12);cout << a << '\n'; // A fi sau a nu fiFuncția
strcmp
Funcția strcmp compară lexicografic șirurile a și b. Adică, le compară caracter cu caracter până când a[i] != b[i], sau până când unul dintre cele două șiruri se termină (asta în cazul în care șirurile sunt egale). Dacă a[i] < b[i], a este mai mic lexicografic decât b, dacă a[i] > b[i], a este mai mare decât b, iar dacă a[i] == b[i], șirurile sunt egale. Din modul de funcționare al funcției putem observa ușor că strcmp are complexitatea unde este cel mai lung prefix comun (longest common prefix) al șirurilor a și b.
Valoarea returnată de strcmp este un număr strict pozitiv dacă a este mai mare decât b, un număr strict negativ dacă a este mai mic decât b, sau 0 dacă șirurile sunt egale. În documentația C++ nu se specifică ce semnificație are valoarea absolută a acestui număr atunci când a și b sunt diferite, dar de multe ori este Însă nu vă bazați pe asta. Am testat acum pe macOS și am primit doar dar pe Windows pot să jur că primeam
cout << (strcmp("interval", "integral") > 0) << '\n'; // 1 ('r' > 'g')cout << (strcmp("C", "C++") < 0) << '\n'; // 1 ('\0' < '+')cout << (!strcmp("string", "string")) << '\n'; // 1Funcția
strchr
Funcția strchr caută prima apariție a caracterului chr în șirul str. Dacă șirul conține acest caracter, se returnează adresa primei sale apariții. Dacă nu, se returnează pointer-ul nul (NULL).
char str[] = "arbore";cout << (strchr(str, 'r') == str + 1) << '\n'; // 1cout << !strchr(str, 'i') << '\n'; // 1cout << strchr(str, 'o') << '\n'; // oreFuncția
strstr
Funcția strstr lucrează foarte asemănător cu strchr, doar că nu caută un caracter, ci un alt string. Mai exact, strstr returnează adresa primei apariții a lui b în șirul a, dacă aceasta există. Dacă nu, se returnează NULL.
char str[] = "debugging";cout << "Am găsit bug-ul la poziția ";cout << (strstr(str, "bug") - str); // 2cout << "!!!\n";// He he, n-am nevoie de StackOverflow!Funcția
strtok
Funcția strtok este folosită pentru împărți șirul str în tokeni, adică în subșiruri separate prin caractere din șirul delim. Mai exact, strtok pune caracterul nul pe fiecare poziție din str ce conține un delimitator, și returnează pe rând câte un pointer la fiecare token obținut. Pentru a realiza asta, va fi necesară o serie de k apeluri, unde k este numărul de tokeni ai lui str.
Primul apel din această secvență va avea forma strtok(str, delim), și va returna un pointer către primul token obținut. Totodată, acest apel anunță funcția că în continuare se va lucra cu string-ul str, pentru că de acum acesta nu va mai fi transmis ca parametru. Următoarele apeluri vor fi de forma strtok(NULL, delim), și fiecare va returna un pointer către următorul token. Dacă vă întrebați cum de știe funcția unde a rămas cu tokenizarea după apelul precedent, răspunsul este că reține această informație într-o variabilă statică. (Variabilele statice din cadrul unei funcții își păstrează valoarea de la apelul precedent.) Iată șablonul pentru tokenizarea unui șir de caractere folosind strtok:
char str[] = "A fost odata ca-n povesti, a fost ca niciodata.";char *p = strtok(str, " .,?!");while (p) { cout << p << '\n'; p = strtok(NULL, " .,?!");}
// A// fost// odata// ca-n// povesti// a// fost// ca// niciodataDe obicei, funcția strtok este folosită pentru a împărți un text în cuvinte, șirul de delimitatori fiind deci semne de punctuație. La fiecare apel, strtok pune '\0' pe fiecare caracter, până dă de unul care nu este delimitator. Apoi, parcurge caractere până găsește din nou un delimitator, pe care pune terminatorul nul pentru ca token-ul găsit să poată fi într-adevăr un string.
Urmează în curând un articol cu probleme simple legate de șiruri de caractere, în care voi arăta cum se pot îmbina aceste funcții. Dacă aveți vreo întrebare despre șiruri de caractere în C++, nu ezitați să o lăsați într-un comentariu mai jos, pentru a vă ajuta 
